这篇文章是看了侯捷讲的STL标准库写的。老先生讲的很细致,但是不免有些繁琐。这里记些笔记,方便以后自己回顾,也是对看的东西的总结。
如题,只是记了STL容器,与容器有关的分配器和迭代器也一并记了。
STL
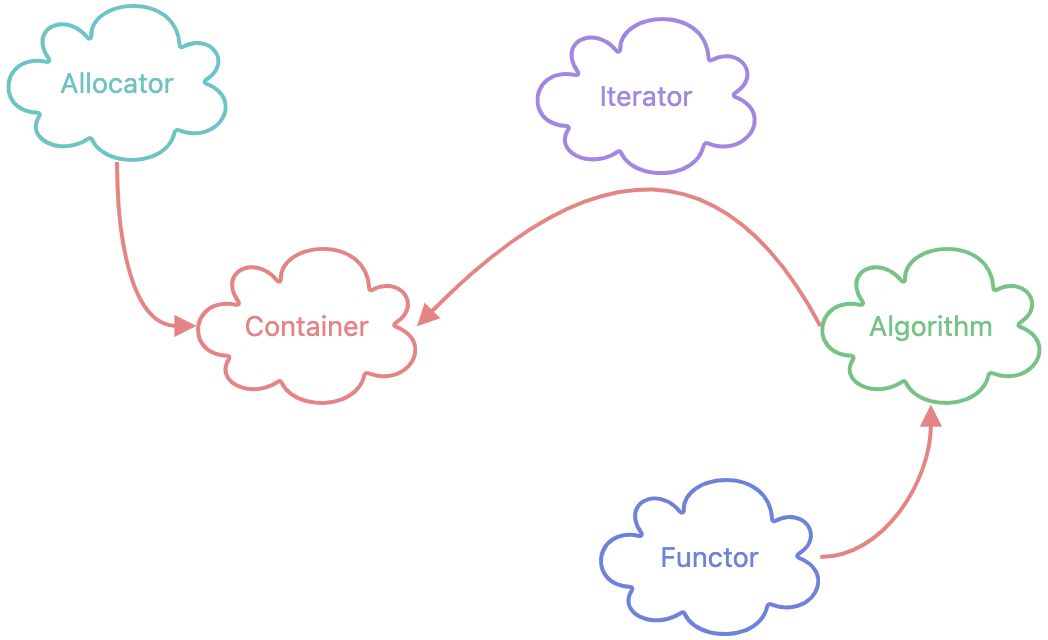
STL(Standard Template Library),标准模版库,是C++提供的基础类库。包括六个部件,
- 容器(Container)
- 分配器(Allocator)
- 算法(Algorithm)
- 迭代器(Iterator)
- 适配器(Adapter)
- 仿函数(Functor)
简单解释这几个部件。容器是一些常用的数据结构,例如vector,unordered_map等;分配器负责处理内存分配的事情;算法是一些常见的算法实现,例如sort,find等;迭代器可以用于遍历容器,也是沟通容器和算法的桥梁;适配器可以理解成一层封装,例如stack是deque的一个适配器;仿函数只是一个实现了operator()的结构体,用于在面向对象的场景下描述函数指针。
用一个简单的程序来使用所有STL部件,
#include <vector>
#include <algorithm>
#include <functional>
#include <iostream>
using namespace std;
int main() {
int ia[6] = {27, 210, 12, 47, 109, 83};
vector<int, allocator<int>> vi(ia, ia+6);
cout << cout_if(vi.begin(), vi.end(),
not1(bind2nd(less<int>(), 40)));
return 0;
}模版以及重载
模版
标准模版库,先简单说下模版。
A template is a C++ entity that defines one of the following:
- a family of classes (class template), which may be nested classes
- a family of functions (function template), which may be member functions
模版提供一种泛化的类或者函数。通过在使用时指定类型,可以将模版限定为某种特殊类型。如下是一个类模版的例子,函数模版类似。
template<typename T>
class complex {
public:
complex(T r = 0, T i = 0) : re(r), im(i) {}
private:
T re, im;
}
complex<double> c1(2.5, 2.5);
complex<int> c2(2, 6);利用模版可以做编译期的计算,又叫模版元编程。模版元编程是图灵完备的。
特化和偏特化
模版本身使用了typename T或者class T来指定类型,这个类型是没有加限制的。如果这个时候有一种需求,对某个特殊类型的模版有特殊实现,则可以使用特化或偏特化。
特化是指将所有的模版类型限制为一种特殊类型,偏特化是指将一部分类型限制为特殊类型。
举个例子,
// 模版
template<class Iterator>
struct iterator_traits {
typedef typename Iterator::iterator_category iterator_category;
}
// 偏特化
template<class T>
struct iterator_traits<T*> {
typedef random_access_iterator_tag iterator_category;
}上述将class Iterator限制为了指针,是偏特化的一种。也可以直接其特化为int,在这种场景下称为全特化。
重载
重载可以指同函数名不同入参,也可以指操作符重载。STL中大量使用了操作符重载,举个例子,
template<class T, class Ref, class Ptr>
struct __list_iterator {
typedef __list_iterator<T, Ref, Ptr> self;
typedef __list_node<T> *link_type;
link_type node;
// 重载
Ref operator*() const { return (*node).data; }
Ptr operator->() const { return &(operator*()); }
}分配器
分配器处理内存分配的事情。如果向容器中加入一个元素,容器需要更多的内存去储存该元素,则容器会通过分配器去向系统请求内存。分配器作为内存管理的抽象,在STL中被大量使用,包括容器、算法等。
template<typename _Tp>
class allocator : public __allocator_base<_Tp>分配器中最重要的两个函数是allocate和deallocate。顾名思义,allocate负责分配内存,deallocate负责销毁内存。在gcc的实现中,默认的分配器是__gnu_cxx::new_allocator<_Tp>,只是对原生new和delete的一层封装。相应的还有其他的分配器,例如__pool_alloc等。
分配器一般作为容器的最后一个模版参数。
template<typename _Tp, typename _Alloc = std::allocator<_Tp> >
class vector : protected _Vector_base<_Tp, _Alloc>这里以vector为例,第二个模版参数是分配器,默认使用std::allocator。
容器
概览
STL容器分为三类,1)顺序容器;2)关联式容器;3)无序容器。
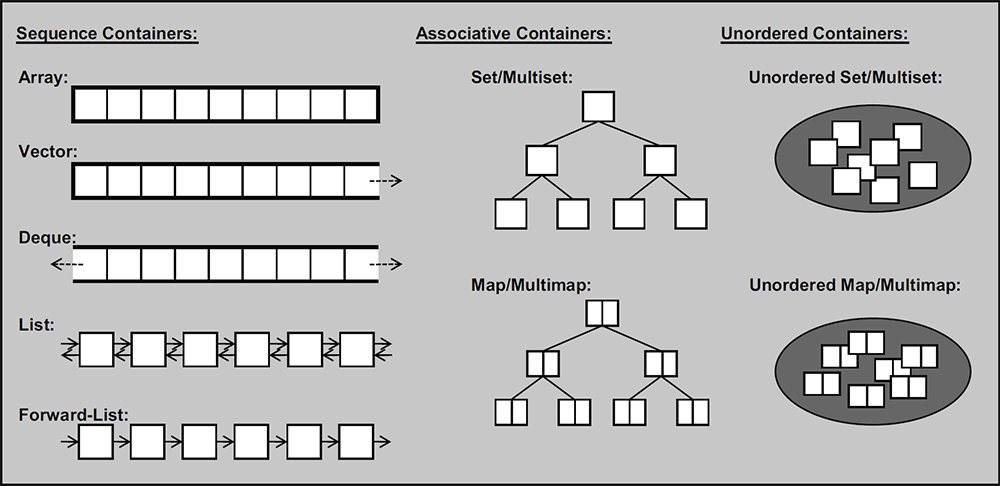
上图展示了STL中的所有容器类型。stack,queue,以及priority_queue都是某种形式的适配器,所以这里没有算进来。
接下来会一一讲述各个容器。
list
先说std::list,双向环形链表。
list中实际上只包含了一个node对象,存前一个node和后一个node的指针,以及数据。
struct _List_node_base {
_List_node_base* _M_next;
_List_node_base* _M_prev;
}
struct _List_node : public _List_node_base {
_Tp _M_data;
}std::list本身非常小,只保存了两个指针,和一个数据对象。其他的数据散落在内存的其他区域,需要访问时再从当前node去找。
a list conceptually represented as A <—> B <—> C <—> D is actually circular; a link exists between A and D. The list class holds (as its only data member) a private list::iterator pointing to D, not to A! To get to the head of the list, we start at the tail and move forward by one. When this member iterator’s next/previous pointers refer to itself, the list is empty.
这里贴的是list源代码中的注释,很清晰地说明了这个数据结构。在list对象中放的是双向环形链表的尾节点,如果这个节点的next指向自身,则list为空。
在访问数据时,list只能顺序访问,从当前的node向之前或之后的node前进。同时,在增加或者删除数据时,list非常高效,只需要修改几个指针值即可。
list本身比较简单,再说list::iterator。当然,list的迭代器也非常简单。直接看代码,
template<typename _Tp>
struct _List_iterator {
_List_node_base* _M_node;
typedef _List_iterator<_Tp> _Self;
// 前向++
_Self&
operator++() _GLIBCXX_NOEXCEPT
{
_M_node = _M_node->_M_next;
return *this;
}
// 后向++
_Self
operator++(int) _GLIBCXX_NOEXCEPT
{
_Self __tmp = *this;
_M_node = _M_node->_M_next;
return __tmp;
}
}list::iterator实际上只持有了一个node指针。以操作后向++为例,只是将持有的node指针置为node->next。其他的同样可以参考源代码。
vector
vector容器实际上是一个可扩容数组。如果容量不够,则会进行扩容。一般来说,每次扩容都会将容量扩大一倍。
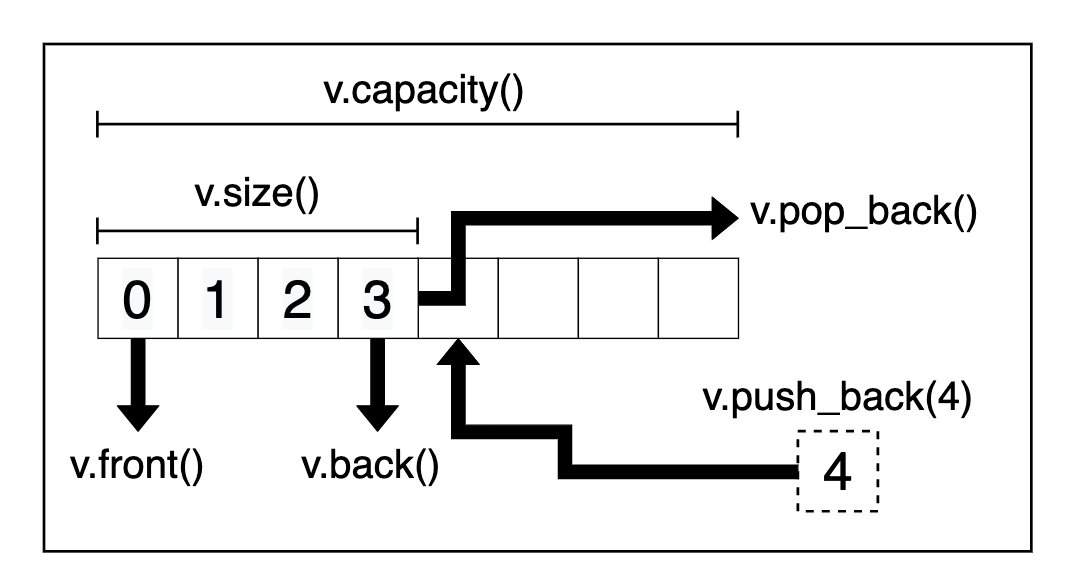
其内部只维护三个指针,
struct _Vector_impl: public _Tp_alloc_type {
pointer _M_start;
pointer _M_finish;
pointer _M_end_of_storage;
}用两个式子可以表述这个容器,
size = _M_finish - _M_start;- capacity =
_M_end_of_storage - _M_start。
一般会先分配一定的内存,用户向其中添加元素。如果内存不够,则向分配器请求一块2 * capacity * sizeof(T)的内存大小,将老的数据拷贝到新内存,然后就可以继续新加元素。通常扩容的步骤非常耗时,如果可以事先确认元素个数,可以使用array,或者使用reserve函数一次性申请所需内存。
vector::iterator是一个指针,
template<typename _Tp, typename _Alloc = std::allocator<_Tp> >
class vector : protected _Vector_base<_Tp, _Alloc> {
typedef _Tp value_type;
typedef value_type *iterator;
}在用vector::iterator访问或者遍历时,与使用一个平凡的指针是一样的。
array
array是一个数组。
template<typename _Tp, std::size_t _Nm>
struct array {
typedef _Tp value_type;
// Support for zero-sized arrays mandatory.
typedef _GLIBCXX_STD_C::__array_traits<_Tp, _Nm> _AT_Type;
typename _AT_Type::_Type _M_elems;
typedef value_type* iterator;
}array不可扩容,注意这里没有Allocator作为模版参数。与vector一样,array::iterator只是一个指针。
红黑树
红黑树是平衡二叉搜索树,保证树的高度平衡,使得查询和插入比较高效。在STL中,set和map使用红黑树作为底层数据结构。
具体维护红黑树的算法这里不做说明,直接看STL中的声明。
// Red-black tree class, designed for use in implementing STL
// associative containers (set, multiset, map, and multimap). The
// insertion and deletion algorithms are based on those in Cormen,
// Leiserson, and Rivest, Introduction to Algorithms (MIT Press,
// 1990), except that
//
// (1) the header cell is maintained with links not only to the root
// but also to the leftmost node of the tree, to enable constant
// time begin(), and to the rightmost node of the tree, to enable
// linear time performance when used with the generic set algorithms
// (set_union, etc.)
//
// (2) when a node being deleted has two children its successor node
// is relinked into its place, rather than copied, so that the only
// iterators invalidated are those referring to the deleted node.
template<typename _Key, typename _Val, typename _KeyOfValue,
typename _Compare, typename _Alloc = allocator<_Val> >
class _Rb_tree {
protected:
typedef __rb_tree_node<_Val> rb_tree_node;
typedef rb_tree_node *link_type;
size_type node_count;
link_type header;
_Compare key_compare;
}红黑树中维护了一个header_cell,其中保存了根节点的指针,同时也保存了最左边节点的指针,以及最右边节点的指针。在用迭代器遍历红黑树时,是从最左边节点开始顺序遍历到最右边节点。
template<typename _Tp>
struct _Rb_tree_iterator {
typedef _Rb_tree_node_base::_Base_ptr _Base_ptr;
_Base_ptr _M_node;
}红黑树的迭代器中包含了一个节点的指针,这个指针中保存了左子节点指针、右子节点指针、父节点指针、自身的颜色以及数据对象。下面可以看到,set和map的迭代器实际上都是红黑树的迭代器。
set
set/multiset以红黑树为底层实现,因此有元素自动排序的特征。
template<typename _Key, typename _Compare = std::less<_Key>,
typename _Alloc = std::allocator<_Key> >
class set {
typedef _Key key_type;
typedef _Key value_type;
typedef _Compare key_compare;
typedef _Rb_tree<key_type, value_type, _Identity<value_type>,
key_compare, _Key_alloc_type> _Rep_type;
_Rep_type _M_t; // Red-black tree representing set.
typedef typename _Rep_type::const_iterator iterator;
}按正常规则遍历set,即可获得元素排序后的状态。set所有的操作,都会转发给底层的红黑树来处理。从这个意义讲,set也是一个容器的Adapter。
set::iterator实际上是红黑树的常量迭代器,这保证了不可以使用set的迭代器来修改内部的元素。
map
map与set类似,底层包含了一个红黑树。
template <typename _Key, typename _Tp, typename _Compare = std::less<_Key>,
typename _Alloc = std::allocator<std::pair<const _Key, _Tp> > >
class map {
public:
typedef _Key key_type;
typedef _Tp mapped_type;
typedef std::pair<const _Key, _Tp> value_type;
typedef _Compare key_compare;
typedef _Alloc allocator_type;
typedef _Rb_tree<key_type, value_type, _Select1st<value_type>,
key_compare, _Pair_alloc_type> _Rep_type;
/// The actual tree structure.
_Rep_type _M_t;
typedef typename _Rep_type::iterator iterator;
}与set不同的是,map的value_type是_Key和_Tp组成的pair。然后在取key时,set使用标准库中的_Identity函数,而map是用的_Select1st函数。
map的迭代器同样只是红黑树的迭代器,由于map向红黑树中声明的value_type是pair<_Key, _Tp>,所以在使用迭代器时,可以直接使用iter->first和iter->second来访问数据。由于_Key是作为红黑树的排序依据,所以不可以使用map迭代器来修改iter->first的值。
一般来说,需要保持元素顺序的话,可以使用set和map。为了维护顺序,需要额外花费时间,所以如果在使用时没有这种需要的话,避免使用以红黑树为底层实现的数据结构。
散列表
无序容器的底层实现都是散列表。散列表在STL中以separate chaining的形式实现,
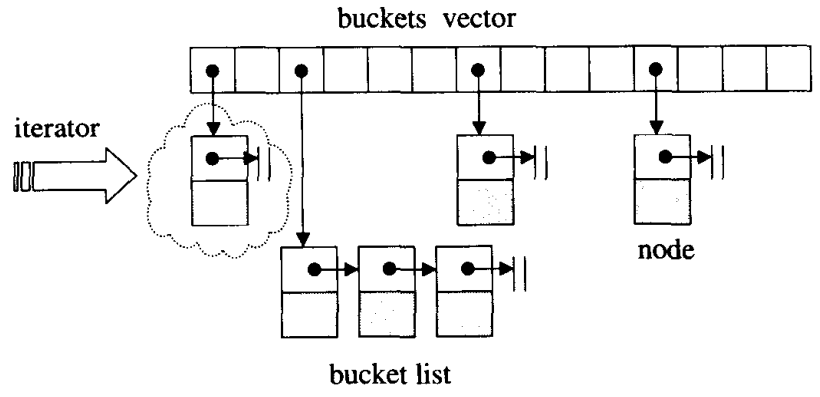
如上图,散列表包括一个buckets vector,以及每一个bucket对应的bucket list。从算法的角度比较好理解,buckets vector的每一个元素表示一个哈希值。对应一个哈希值,有可能有多个元素,这些元素都被链接到同一个bucket list上。 同样用几个式子来表述这个数据结构,
bucket_count = buckets_vector.size();element_count = bucket_list1.size() + .. + bucket_listn.size();load_factor = element_count / bucket_count。
这些数据都可以通过API来获取。bucket_count指目前的槽位数,element_count指当前容器内的元素总数。load_factor衡量当前容器的拥挤程度,如果load_factor = 2,就代表平均一个槽位要装下两个元素。一般来说,max_load_factor会设置为1。
Each
_Hashtabledata structure has:
Bucket[] _M_bucketsHash_node_base _M_before_beginsize_type _M_bucket_countsize_type _M_element_countwith Bucket being
Hash_node*and_Hash_nodecontaining:
_Hash_node* _M_nextTp _M_valuesize_t _M_hash_codeif cache_hash_code is trueIn terms of Standard containers the hashtable is like the aggregation of:
std::forward_list<_Node>containing the elementsstd::vector<std::forward_list<_Node>::iterator>representing the buckets
上面的引用来自源代码中的注释,很清晰地阐述了hashtable的构成。
在平均情况下,散列表的大多数操作(包括查找,插入,删除)都能在常数时间复杂度内完成,相较于关联式容器与容器大小成对数的时间复杂度更加优秀。
一般来说,当元素个数大于bucket个数时,即**load_factor > 1**,会进行rehash。也就是将bucket vector扩大将近一倍,然后将元素重新链接到buckets vector下。这是一个非常耗时的操作。
hashtable::iterator中包含了一个node指针,就是在bucket list中一个单独的node。具体代码这里就不贴了。
unordered_set
unordered_set底层是一个hashtable。
template<typename _Value,
typename _Hash = hash<_Value>,
typename _Pred = equal_to<_Value>,
typename _Alloc = allocator<_Value>>
class unordered_set {
typedef __uset_hashtable<_Value, _Hash, _Pred, _Alloc> _Hashtable;
_Hashtable _M_h;
}默认的_Hash用了标准库的hash函数。如果用到了自定义的类,或者认为自己设计的哈希函数可以更好地避免冲突,这里也可以写自定义的哈希函数。
对unordered_set的操作实际上最终都转发给了hashtable,
// 向unordered_set插入initializer_list
void insert(initializer_list<value_type> __l){
_M_h.insert(__l);
}unordered_map
unordered_map底层同样是一个hashtable。
template<typename _Key,
typename _Tp,
typename _Hash = hash<_Key>,
typename _Pred = std::equal_to<_Key>,
typename _Alloc = std::allocator<std::pair<const _Key, _Tp> >,
typename _Tr = __umap_traits<__cache_default<_Key, _Hash>::value>>
using __umap_hashtable = _Hashtable<_Key, std::pair<const _Key, _Tp>,
_Alloc, __detail::_Select1st,
_Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;可以看到,内部哈希表的节点数据是std::pair<const _Key, _Tp>。
迭代器
上文讲了很多迭代器。例如,list::iterator是一个单独的类,其中包含了一个node指针;而vector::iterator就是一个指向容器内部地址的指针。
这里对迭代器做一个小总结。迭代器分为五类,
struct input_iterator_tag {};
struct output_iterator_tag {};
// 只能向前
struct forward_iterator_tag : public input_iterator_tag {};
// 可以向前向后
struct bidirectional_iterator_tag : public forward_iterator_tag {};
// 可以任意取址
struct random_access_iterator_tag : public bidirectional_iterator_tag {};list::iterator是bidirectional_iterator_tag,vector::iterator是random_access_iterator_tag,forward_list::iterator是forward_iterator_tag。forward_list在前文中没有讲,这是一个STL中的单向链表,比较简单所以没有多加描述。
这里举一个例子,表述迭代器的种类对算法的影响,
/// This is an overload used by find algos for the Input Iterator case.
template<typename _InputIterator, typename _Predicate>
inline _InputIterator
__find_if(_InputIterator __first, _InputIterator __last,
_Predicate __pred, input_iterator_tag)
{
while (__first != __last && !__pred(__first))
++__first;
return __first;
}
/// This is an overload used by find algos for the RAI case.
template<typename _RandomAccessIterator, typename _Predicate>
_RandomAccessIterator
__find_if(_RandomAccessIterator __first, _RandomAccessIterator __last,
_Predicate __pred, random_access_iterator_tag)
{
typename iterator_traits<_RandomAccessIterator>::difference_type
__trip_count = (__last - __first) >> 2;
for (; __trip_count > 0; --__trip_count)
{
if (__pred(__first))
return __first;
++__first;
if (__pred(__first))
return __first;
++__first;
if (__pred(__first))
return __first;
++__first;
if (__pred(__first))
return __first;
++__first;
}
switch (__last - __first)
{
case 3:
if (__pred(__first))
return __first;
++__first;
case 2:
if (__pred(__first))
return __first;
++__first;
case 1:
if (__pred(__first))
return __first;
++__first;
case 0:
default:
return __last;
}
}可以看到,依据迭代器的不同,算法进行了不同的处理。对于_InputIterator,只能一个接一个找next指针。而对于_RandomAccessIterator,由于可以随机寻址,所以利用了内存的连续性做循环展开,以提高查询的效率。
总结
这篇讲述了一些STL中用到的基础技术。然后简单说明了分配器,逐个说明了容器及其迭代器。有一些容器有特殊属性需要关注,例如vector的扩容,hashtable的rehash。最后提了一下迭代器的种类,以及其对算法的影响。