从JS到WASM
在Web的世界里,JavaScript是最主流的语言,没有之一。
简单说JavaScript的特点,1. 动态语言,变量的类型在运行时确定;2. 解释执行,有JIT机制进行运行时优化,但仍然比C、Rust等编译型选手慢。
其他特点,例如灵活、面向对象等,与本文关联不大,这里不做讨论。
因为动态,所以需要在运行时绑定类型,运行速度慢。因为解释执行,没有编译过程中的大量优化,运行速度慢。
但是在Web中,有时候需要进行大量的计算,例如在网页中识别人脸,需要跑一个神经网络模型;例如在网页上做建模,需要大量的数学推导。这时JavaScript的性能就无法满足需求了,用JavaScript写出来的推理引擎或者建模软件,延迟高,用户体验差。
于是有了WASM,也就是WebAssembly。
WebAssembly is a low-level, portable bytecode that is designed to be encoded in a compact binary format and executed at near-native speed in a memory-safe sandbox.
可以理解为,WebAssembly是一种接近机器层面的字节码,浏览器可以将其转化为机器码并执行。
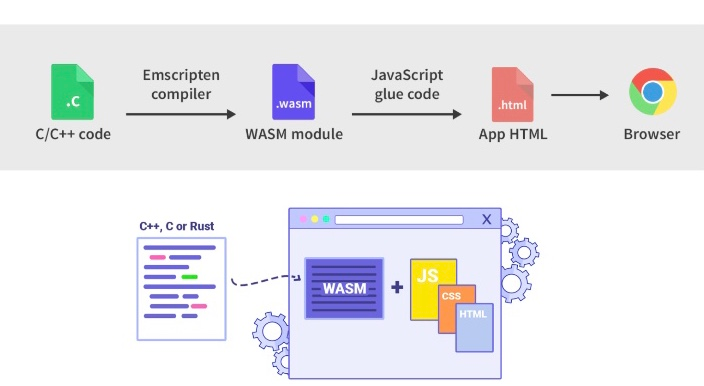
一般来说,使用高级语言(例如C/C++、Rust)写出来的代码通过某些编译器可以得到WASM代码,也称WASM是这些编译器的target,例如对于C/C++来说,通过Emscripten compiler编译出WASM。.wasm文件通过JS胶水代码加载进内存并实例化,然后就可以从JS调用WASM实现的逻辑。
对WebAssembly的加载以及执行有兴趣的话,可以参考这篇文章,这里不做赘述。
WASM相比JS来说,有两个优势:1. 快,相同的实现逻辑快两到三倍;2. .wasm文件体积小,结构更紧凑,便于网络传输。
如下图,通过Emscripten编译器将C/C++代码编译成WASM module,然后通过JavaScript胶水代码将WASM module读取到内存中并执行。
用WASM写算子
Web端的推理引擎会采用WASM加速,例如TFjs的WASM后端。
推理引擎中的算子部分会用C/C++实现,编译成WASM module,待使用时加载。算子的调度部分用JS实现,包括计算图的构建和内存复用等。
给个例子,ReLU算子。
算子的部分用C++完成。
#include <emscripten.h>
float __max(float a, float b) {
return a > b ? a : b;
}
extern "C" {
EMSCRIPTEN_KEEPALIVE
void ReLU(float *input, int sz, float *output) {
while (sz--) {
*(input++) = __max(*(output++), 0);
}
}
}然后用Emscripten编译上述C++代码,target设置为WASM。
➜ em++ -std=c++11 relu.cc -Os -s WASM=1 --no-entry -o relu.wasm解释一下命令行中的几个参数,-std:C++代码的标准,这里用c++11;-Os:优化等级;-s WASM=1编译的target设置为WASM;--no-entry:代码中没有main函数;-o relu.wasm:输出文件名。
这样就得到了一个.wasm文件。
在C++代码中,宏EMSCRIPTEN_KEEPALIVE,是告诉编译器不要优化删除这个函数。因为ReLU函数没有被C++代码的其他地方用到,编译器会将这一部分代码视为冗余,但实际上这个函数是在C++代码的外部被调用的。
然后是JavaScript代码,为了方便直接在HTML中写JS了,没有用node之类的JS环境。
<!-- relu.html -->
<script>
const importObject = {
module: {},
env: {
memory: new WebAssembly.Memory({ initial: 256, maximum: 32768, shared: true }),
}
};
fetch('relu.wasm').then(response =>
response.arrayBuffer()
).then(bytes =>
WebAssembly.instantiate(bytes, importObject)
).then(results => {
console.log(results.instance.exports)
const ReLU = results.instance.exports.ReLU
const memory = results.instance.exports.memory
const sz = 5
const input = new Float32Array(memory.buffer, 0, sz)
input.set([-3, 15, -18, 4, 2])
console.log(input)
const output = new Float32Array(memory.buffer, 0, sz)
ReLU(input.byteOffset, sz, output.byteOffset)
console.log(output)
});
</script>这段代码主要有三个值得注意的地方。
- 初始化WASM module:这里以文件的形式拉取
relu.wasm,然后将返回得到的arrayBuffer传入初始化WebAssembly的API。这里的WebAssembly是浏览器提供的处理WASM的库,具体可以参考这里。 - WASM module中的函数存在于
module.instance.exports对象中。 - 在初始化的时候传入的
importObject对象中,有一个env.memory属性,对应设置了一块可供JS和WASM共享的内存,利用这个内存将JS中的数据传入到WASM中,然后在WASM中做处理。
用浏览器打开relu.html,在Terminal中可以看到以下输出
> Object { memory: WebAssembly.Memory, ReLU: 1(), __indirect_function_table: WebAssembly.Table, _initialize: 0(), __errno_location: 5(), stackSave: 2(), stackRestore: 3(), stackAlloc: 4() }
> Float32Array(5) [ -3, 15, -18, 4, 2 ]
> Float32Array(5) [ 0, 15, 0, 4, 2 ]输出结果符合预期。
简单来说,用WASM写算子就是,用C/C++(Rust也行)写好算子的实现逻辑,用对应的编译器生成.wasm文件,在JS代码中加载.wasm,从WASM module中拿到对应的函数,然后分配共享内存,进行计算。
SIMD
Single Instruction Multiple Data.
以扩展指令集的方式支持数据并行。
#include <wasm_simd128.h>
#include "memory.h"
size_t width = 32;
float *out = (float *) malloc(width * sizeof(float));
float *in0 = (float *) malloc(width * sizeof(float));
float *in1 = (float *) malloc(width * sizeof(float));
/* fill in in0 and in1 */
// scalar
for (int i = 0; i < width; i++) {
out[i] = in0[i] + in1[i];
}
// simd
for (int i = 0; i < width + 3; i += 4) {
const v128_t vecA = wasm_v128_load(in0);
const v128_t vecB = wasm_v128_load(in1);
v128_t r = wasm_f32x4_add(vecA, vecB);
wasm_v128_store(out, r);
in0 += 4, in1 += 4;
out += 4;
}
free(out), free(in0), free(in1);如上,通过引入wasm_simd128.h这个头文件,可以使用例如wasm_v128_load、wasm_f32x4_add这类的intrinsics函数。每次将四个浮点数加载进寄存器,然后一次性进行四次加法。这样增加了程序的数据吞吐量,提升性能。
更多关于SIMD的信息参考这里。
这里有一个XNNPACK中实现的GEMM kernel可供参考。
通过引入SIMD可以编写更高性能的WASM算子。编译器有时也会进行相关的优化,例如,对Emscripten开启某些编译选项之后就使编译器开启自动向量化。
Emscripten supports the WebAssembly SIMD proposal when using the WebAssembly LLVM backend. To enable SIMD, pass the -msimd128 flag at compile time. This will also turn on LLVM’s autovectorization passes, so no source modifications are necessary to benefit from SIMD.
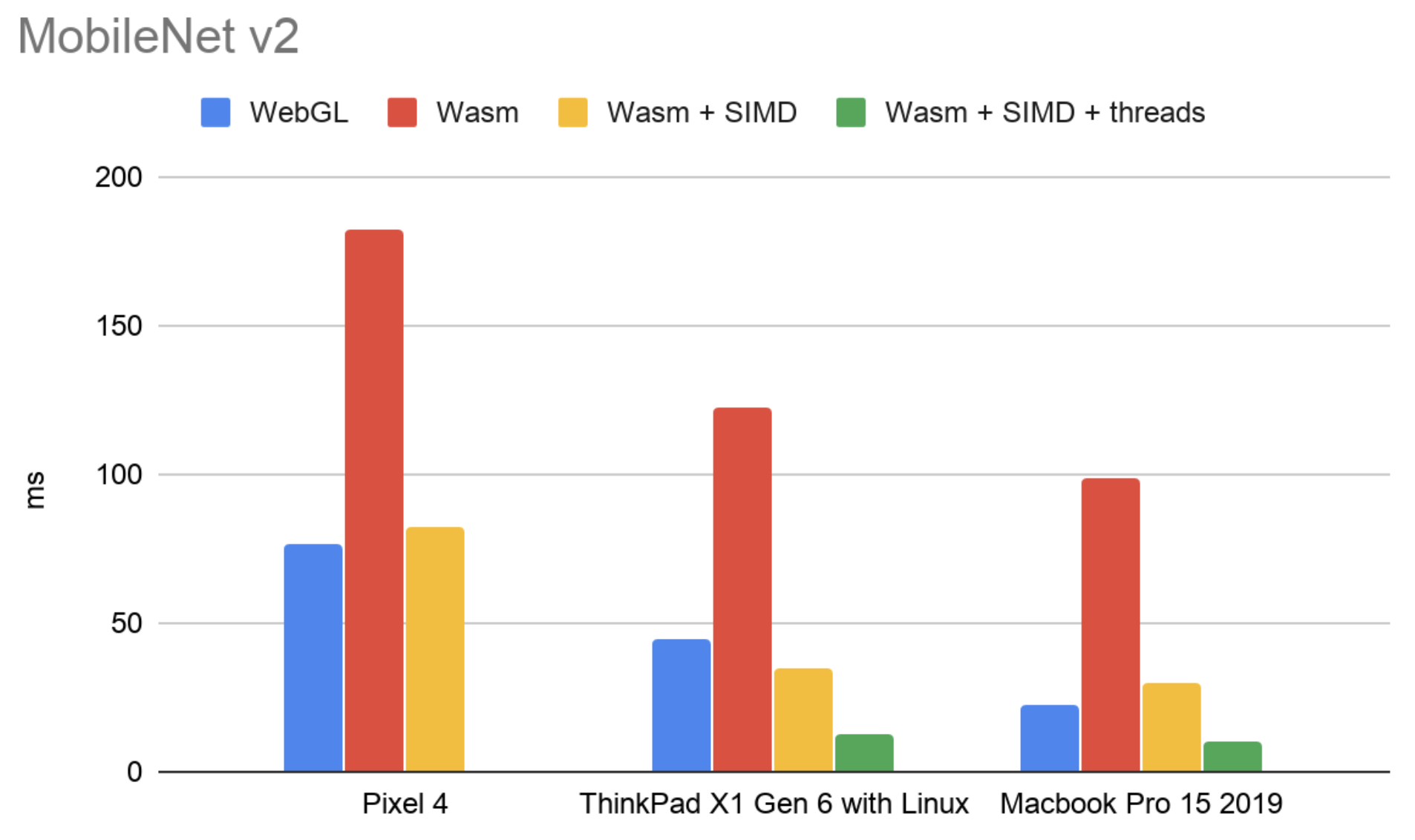
TFjs进行的一些实验,比较开启SIMD和利用多线程后推理的性能,可以看到,使用SIMD之后,推理速度快了将近四倍。
多线程
一般通过引入线程池的方式使用多线程。
在web中,JavaScript的执行是单线程的,多线程通过web worker的方式实现。对于Emscripten来说,需要加入编译参数-pthread开启多线程支持,更多信息可以参考文档。
使用多线程的形式,是将一个算子的计算进行分块,然后将不同块分配给不同的线程进行计算。例如,一个加法算子,输入维度为[1024],则可以将数据分成4个输入维度为[256]分配给四个线程计算。
在tfjs中,使用pthreadpool这个线程池进行多线程的加速,这个线程池用bazel构建,看到对应的构建脚本
linkopts = select({
":emscripten_with_threads": [
"-s ALLOW_BLOCKING_ON_MAIN_THREAD=1",
"-s PTHREAD_POOL_SIZE=8",
],
"//conditions:default": [],
})可以发现TFjs允许阻塞主线程,并且采用了一个有八个线程的线程池。
Misc
- 初始化wasm module时,通过设置传入的importObject,可以向WASM中传入JS的函数,也就是可以从WASM中调用JS。
relu.html运行时可能遇到CORS的问题,需要配置浏览器的安全选项绕过。- Chrome开启多线程的时候会遇到SharedArrayBuffer被禁止使用的问题,需要配置服务器的header绕过。